Text mining
Readings and class materials for Tuesday, November 28, 2023
Suggested materials
Supervised Machine Learning for Text Analysis in R
Silge’s Youtube Channel & Blog
Why?
Textual data plays an important role in various areas of economics. These unstructured data sources typically require significant cleansing and processing procedures in order to extract information from them. This is where Natural Language Processing (NLP) comes into play, helping to interpret and structure these texts, facilitating a better understanding of economic trends, market behavior, consumer sentiment, political influences, and many other factors. An example of this is that by utilizing NLP technology, economic reports, banking documents, and other textual data can be transformed into structured formats, enabling a better and deeper understanding of monetary policy impacts. In contemporary research, it is essential for a master student to familiarize themselves with textual data from various perspectives.
The texts might be the thing our research focuses on (such as communication and marketing topics).
A substantial portion of our generated data arrives in textual form. Processing textual data is crucial for addressing numerous research questions, such as generating daily sentiment indexes.
In many cases, text-based models can provide excellent narratives to complement our econometric models (as discussed later).
What?
Text mining is the process of extracting useful information from unstructured data. It is a broad term that covers a variety of techniques for analyzing textual data. Text mining is a subset of the field of Natural Language Processing (NLP), which is concerned with building systems that analyze and understand natural language. Text mining is a way to obtain insights from unstructured data. It is a process that involves structuring the input text, deriving patterns within the structured data, and finally evaluating and interpreting the output. Text mining is a multi-disciplinary field based on information retrieval, data mining, machine learning, statistics, and computational linguistics.
The following presentation is an illustration of the toolkit that have been used related to the central bank communication.
How? (Yes, in a tidy approach)
Lets recall our concepts about tidy data principles. This involve structuring datasets so that each variable is a column, each observation is a row, and each type of observational unit forms a table. Applying these principles to text mining, especially in economic research, facilitates more efficient and effective data analysis.
In the context of text mining, tidy text means that each row of the dataset represents a single observation about a single token (usually a word). This format is particularly useful for economic texts, as it allows for straightforward application of various text mining techniques and visualisations[^Many text mining packages have their own specific workflow (mainly for efficiency reasons), which is the opposite of this. For example STM is a mess sometimes or you can only run certain models in python. The reticulate package might help.].
Tokens
A token is a single entity, usually a word, that is a component of a larger text. Tokenization is the process of breaking a text into tokens. The simplest way to tokenize a text is to split it into individual words. This is a good starting point, but it is not sufficient for most text mining applications. For example, the words “run”, “runs”, and “running” are all forms of the same verb, and it is useful to treat them as the same token. This process is called stemming.
Another example is that the words “United States” are a single token, and it is useful to treat them as such. This process is called n-grams. n-grams are tokens that are made up of n words. For example, “United States” is a 2-gram, and “United States of America” is a 4-gram. I personally find them useful to filter out repeating marketing slogans from the text (What are the longest n words that frequently appear together), and to interpret models that are based on words.
For example in the following presentation I use 2-grams to understand that why certain words might correlate with low/high airbnb rating. The original TDK paper is also available.
Term Frequency and Inverse Document Frequency (TF-IDF)
TF-IDF is a statistical measure used to understand the importance of words in a document set. In economics, TF-IDF can be used to identify key terms in a large corpus of economic literature, highlighting prevalent themes or topics. TF-IDF is a product of two statistics, term frequency and inverse document frequency. Term frequency is the number of times a term appears in a document. Inverse document frequency is the inverse of the number of documents in which a term appears. The TF-IDF statistic is the product of these two statistics. The higher the TF-IDF statistic, the more important the term is to the document. The following presentation is an example of this. This method will identify words that frequently appear in the given document but do not appear elsewhere. This is useful for identifying key terms in a document set (here: blog post of one author).
Sentiment analysis
Sentiment analysis is the process of determining the emotional tone behind a series of words, used to gain an understanding of the the attitudes, opinions and emotions expressed within an online mention. Sentiment analysis is extremely useful in social media monitoring as it allows us to gain an overview of the wider public opinion behind certain topics. In economics, sentiment analysis can be used to understand the tone of central bank communication, expectations or public sentiment.
The following presentation is an example of the latter.
Topic modeling
Topic modeling is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body. Intuitively, given that a document is about a particular topic, one would expect particular words to appear in the document more or less frequently: “dog” and “bone” will appear more often in documents about dogs, “cat” and “meow” will appear in documents about cats, and “the” and “is” will appear equally in both. A document typically concerns multiple topics in different proportions; thus, in a document that is 10% about cats and 90% about dogs, there would probably be about 9 times more dog words than cat words. A topic model captures this intuition in a mathematical framework, which allows examining a set of documents and discovering, based on the statistics of the words in each, what the topics might be and what each document’s balance of topics is.
The most frequenlty seen method is the Latent Dirichlet Allocation (LDA) model. LDA is based on the assumption that documents are mixtures of topics, where a topic is defined as a distribution over words. This model allows for each document in a corpus to be described by a distribution of topics, and each topic to be characterized by a distribution of words.
Initialization: LDA starts by assigning each word in each document to a random topic. This initial assignment gives both topic representations for all the documents and word distributions for all the topics.
Iterative Process: The model then iteratively updates these assignments. For each word in a document, LDA adjusts the topic assignment based on two factors:
How prevalent is each topic in the document?
How prevalent is each word in the topics?
- Convergence: This process is repeated until the assignments reach a steady state, which is the model’s output.
But how many topics?
The number of topics is the only tuned hyperparameter of the model. Too few topics will produce overly broad results and it is impossible to interpret them, while choosing too many topics will result in the “over-clustering” of a corpus into many small, highly similar topics. Similar to clustering methods, there are rules to determine the optimal value of this parameter, for example, semantic cohesion and exclusivity, but we apply a different framework, because of the interest in one topic or it would result too many topics.
How to interpret the results?
The results of the model are the topic-word and document-topic distributions. The topic-word distribution is a matrix of words and topics, where each cell represents the probability of a word appearing in a given topic. The document-topic distribution is a matrix of documents and topics, where each cell represents the probability of a document belonging to a given topic. The following presentation is an example of this. This method will identify topics that frequently appear in the given document but do not appear elsewhere. This is useful for identifying key topics in a document set (here: blog post of one author).
get_links <- (. %>%
read_html() %>%
html_nodes("a") %>%
html_attr("href") %>%
na.omit() %>%
unique() %>%
keep(str_detect, pattern = "https://economaniablog.hu/") %>%
keep(str_detect, pattern = "hu/tag/|hu/author/|hu/bloggerek/", negate = T) %>%
keep(str_detect, pattern = "hu/about/|hu/kapcsolat/|hu/tanulj_tolunk/|hu/szakmai_muhely/|hu/category/|#comments|hu/page/", negate = T) %>%
setdiff("https://economaniablog.hu/")) %>%
possibly(otherwise = NA_character_)
article_links <- str_c("https://economaniablog.hu/page/", 1:40, "/") %>%
map(get_links) %>%
reduce(c) %>%
na.omit()
get_text <- function(p, node) {
p %>%
html_nodes(node) %>%
html_text()
}
economania_raw_df <- tibble(article_links) %>%
sample_frac(.1) |>
mutate(
p = map(article_links, insistently(read_html), .progress = TRUE),
text = map(p, get_text, node = "p"),
title = map(p, get_text, node = "h1.entry-title"),
title = map_chr(title, first),
author = map(p, possibly(get_text), node = ".byline a"),
author = map(author, first),
)
find_author <- function(author_condition, text) {
author <- author_condition
if (author_condition == "X" | is.na(author_condition)) {
author <- "X"
for (i in x_authors) {
if (any(str_detect(text, pattern = i))) {
author <- i
break
}
}
}
author
}
x_authors <- c("Granát Marcell",
"Sulyok András",
"Marczis Dávid",
"Szabadkai Dániel",
"Lóránt Balázs",
"Nagy Olivér",
"Malatinszky Gábor",
"Várgedó Bálint",
"Nagy Márton",
"Bartha Kristóf",
"Heilmann István",
"Várgedő Bálint",
"Kiss-Mihály Norbert",
"Tófalvi Nóra",
"Kálmán Péter",
"Moldicz Csaba",
"Nagy Benjámin",
"Rácz Olivér",
"Tóth Gábor",
"Mikó Szabolcs",
"Csontos Tamás Tibor",
"Siket Bence",
"Szalai Zoltán",
"Horváth Dániel",
"Hardi Zsuzsanna és Szapáry György",
"Pavelka Alexandra",
"Horváth Gábor",
"Balázs Flóra",
"Dancsik Bálint",
"Marincsák Kálmán Árpád",
"Farkas Sára és Gutpintér Júlia",
"Palotai Dániel",
"dr. Csillik Péter és Gutpintér Júlia",
"Oliver Knels")
economania_df <- economania_raw_df %>%
select(-p) %>%
distinct(article_links, .keep_all = TRUE) %>%
mutate(
author_cleaned = map2_chr(author, text, find_author),
text = map(text, setdiff, y = "Economania blog"),
text = map(text, .f = function(t) discard(t, str_detect, "View all")),
text = map(text, .f = function(t) discard(t, str_detect, "Főoldali kép forrása:")),
text = map(text, .f = function(t) discard(t, str_detect, "Hozzászólások letiltva.")),
text = map_chr(text, str_flatten, " "),
text = map2_chr(text, author, ~ gsub(str_c(gsub("és.*", "", .y), ".*"), "", .x)),
text = gsub(" Hivatkozások.*", "", text),
text = gsub(" References.*", "", text),
lang = textcat::textcat(text),
time = str_extract(article_links, "20\\d\\d/\\d\\d/\\d\\d"),
time = lubridate::ymd(time)
) |>
drop_na(text)
write_rds(economania_df, file = "economania_df.rds")library(tidytext)
economania_df %>%
filter(lang == "hungarian") |>
select(author = author_cleaned, time, text) |>
unnest_tokens(word, text) |>
mutate(
word = SnowballC::wordStem(word, language = "hungarian")
) |>
count(author, word) |>
bind_tf_idf(word, author, n)# A tibble: 10,976 × 6
author word n tf idf tf_idf
<chr> <chr> <int> <dbl> <dbl> <dbl>
1 Baranyai Eszter 1 3 0.00214 0.442 0.000945
2 Baranyai Eszter 10 1 0.000713 0.693 0.000494
3 Baranyai Eszter 11 1 0.000713 1.95 0.00139
4 Baranyai Eszter 12 1 0.000713 1.54 0.00110
5 Baranyai Eszter 14 2 0.00143 2.64 0.00376
6 Baranyai Eszter 15 1 0.000713 1.54 0.00110
7 Baranyai Eszter 1963 1 0.000713 2.64 0.00188
8 Baranyai Eszter 1971 1 0.000713 2.64 0.00188
9 Baranyai Eszter 1995 1 0.000713 2.64 0.00188
10 Baranyai Eszter 2 2 0.00143 0.693 0.000988
# ℹ 10,966 more rowsfit <- economania_df %>%
filter(lang == "hungarian") |>
select(title, text) |>
unnest_tokens(word, text) |>
mutate(
word = SnowballC::wordStem(word, language = "hungarian")
) |>
filter(!str_detect(word, "\\d"), str_length(word) >= 3) |>
anti_join(tibble(word = stopwords::stopwords("hu"))) |>
count(title, word) |>
cast_dtm(title, word, n) |>
topicmodels::LDA(k = 5, control = list(seed = 1234))
tidy(fit, matrix = "beta")# A tibble: 27,470 × 3
topic term beta
<int> <chr> <dbl>
1 1 aggódn 2.25e-81
2 2 aggódn 2.75e- 4
3 3 aggódn 2.96e-81
4 4 aggódn 2.61e-81
5 5 aggódn 3.01e-81
6 1 alap 1.53e- 3
7 2 alap 6.53e- 3
8 3 alap 1.70e- 3
9 4 alap 1.47e- 3
10 5 alap 5.51e- 3
# ℹ 27,460 more rowsfit |>
tidy(matrix = "beta") |>
group_by(topic) |>
slice_max(beta, n = 10) |>
summarise(top_words = str_flatten(term, ", "))# A tibble: 5 × 2
topic top_words
<int> <chr>
1 1 gazdaság, modell, min, növekedés, járvány, eset, kín, esg, hatás, eredm…
2 2 index, min, ember, alap, piac, kérdés, eset, írás, szerin, oly
3 3 min, pénz, mérleg, pénzügy, ped, fizetés, szint, zöl, kar, százale
4 4 min, virtuális, jegyban, szerin, jegyba, eset, infláció, válság, világ,…
5 5 egyetem, rangsor, kutatás, egyet, intézmény, szám, min, hatás, pénzügy,…tidy(fit, matrix = "gamma")# A tibble: 170 × 3
document topic gamma
<chr> <int> <dbl>
1 A 2019-es év 8 legnépszerűbb írása blogunkon 1 2.95e-5
2 A Homo Economicus karikatúrája a 19. századból 1 1.87e-5
3 A koronavírus kriptoáldozatai 1 1.98e-5
4 A közgazdaságtan viszonya a természetes világhoz 1 8.87e-1
5 A pertársaság és következményei az Egyesült Államokban 1 2.38e-5
6 A világ legegyszerűbb és egyben legbonyolultabb pénzügyi kérdé… 1 2.56e-5
7 Amikor úgy tűnt, hogy Luxemburgnak van beleszólása – vagy mégs… 1 2.38e-5
8 Beszéljünk a profitokról is! 1 2.41e-5
9 Csőstül jön a baj – ezért fáj különösen a mostani válság 1 4.83e-5
10 Célzott beavatkozási pont a lakáshitelek piacán: az NHP Zöld O… 1 1.90e-5
# ℹ 160 more rowstopics_by_document <- tidy(fit, matrix = "gamma") |>
pivot_wider(names_from = topic, values_from = gamma, names_prefix = "topic_") |>
rename(title = document)
topics_by_document# A tibble: 34 × 6
title topic_1 topic_2 topic_3 topic_4 topic_5
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 A 2019-es év 8 legnépszerűbb írása b… 2.95e-5 1.00e+0 2.95e-5 2.95e-5 2.95e-5
2 A Homo Economicus karikatúrája a 19.… 1.87e-5 1.00e+0 1.87e-5 1.87e-5 1.87e-5
3 A koronavírus kriptoáldozatai 1.98e-5 1.98e-5 1.98e-5 1.00e+0 1.98e-5
4 A közgazdaságtan viszonya a természe… 8.87e-1 1.13e-1 2.82e-5 2.82e-5 2.82e-5
5 A pertársaság és következményei az E… 2.38e-5 2.38e-5 2.38e-5 2.38e-5 1.00e+0
6 A világ legegyszerűbb és egyben legb… 2.56e-5 2.56e-5 1.00e+0 2.56e-5 2.56e-5
7 Amikor úgy tűnt, hogy Luxemburgnak v… 2.38e-5 9.11e-1 2.38e-5 2.38e-5 8.94e-2
8 Beszéljünk a profitokról is! 2.41e-5 2.41e-5 2.41e-5 1.00e+0 2.41e-5
9 Csőstül jön a baj – ezért fáj különö… 4.83e-5 4.83e-5 4.83e-5 1.00e+0 4.83e-5
10 Célzott beavatkozási pont a lakáshit… 1.90e-5 1.90e-5 1.00e+0 1.90e-5 1.90e-5
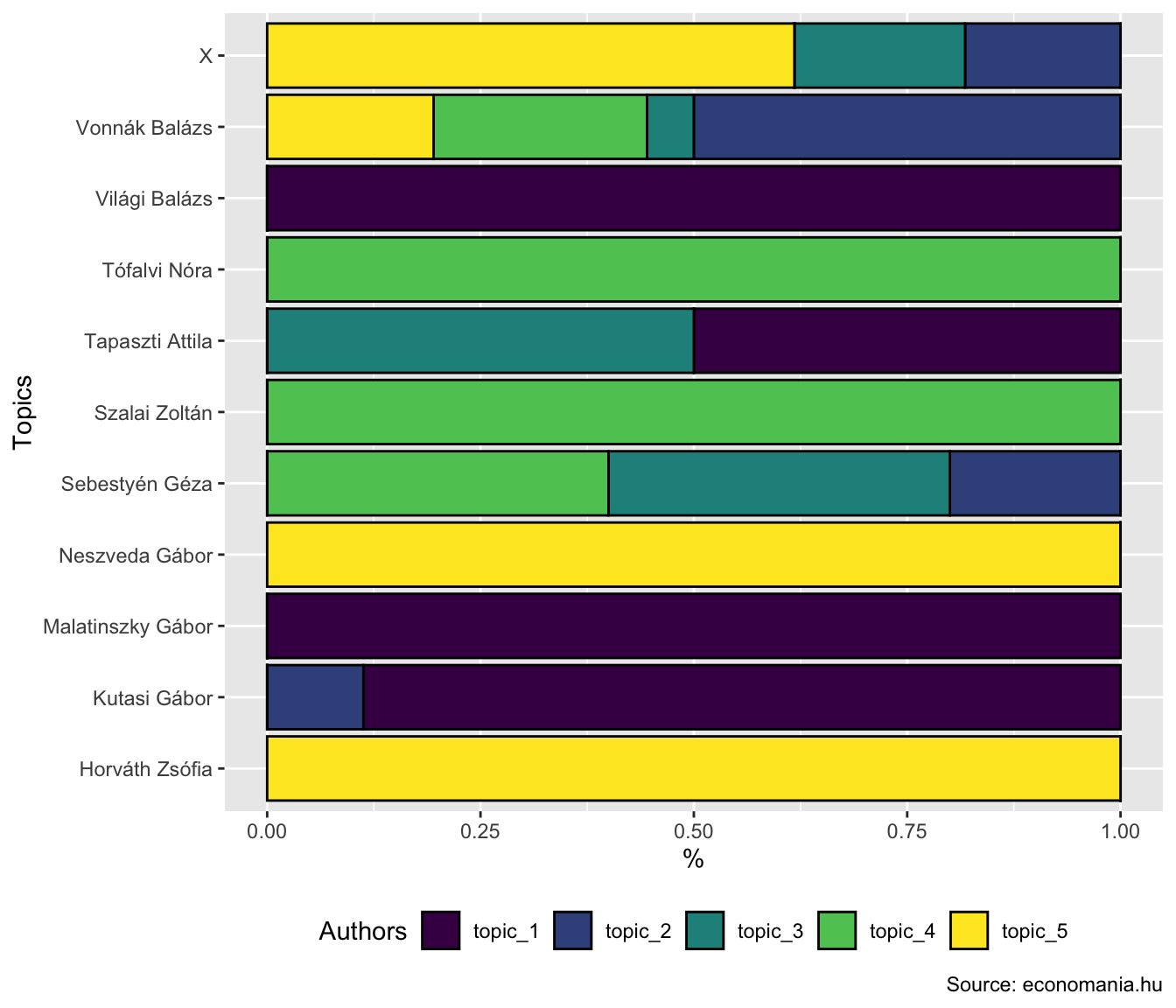
# ℹ 24 more rowstopics_by_author <- economania_df |>
left_join(topics_by_document, by = "title") |>
group_by(author = author_cleaned) |>
summarise(
across(starts_with("topic"), sum)
) |>
drop_na()
topics_by_author# A tibble: 11 × 6
author topic_1 topic_2 topic_3 topic_4 topic_5
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Horváth Zsófia 0.0000123 0.0000123 0.0000123 0.0000123 1.00
2 Kutasi Gábor 0.887 0.113 0.0000282 0.0000282 0.0000282
3 Malatinszky Gábor 1.00 0.0000219 0.0000219 0.0000219 0.0000219
4 Neszveda Gábor 0.0000542 0.0000542 0.0000542 0.0000542 1.00
5 Sebestyén Géza 0.000132 1.00 2.00 2.00 0.000132
6 Szalai Zoltán 0.0000148 0.0000148 0.0000148 1.00 0.0000148
7 Tapaszti Attila 1.00 0.0000378 1.00 0.0000378 0.0000378
8 Tófalvi Nóra 0.0000250 0.0000250 0.0000250 1.00 0.0000250
9 Világi Balázs 2.00 0.0000288 0.0000288 0.0000288 0.0000288
10 Vonnák Balázs 0.000264 2.00 0.219 1.00 0.780
11 X 0.000146 0.911 1.00 0.000146 3.09 topics_by_author |>
pivot_longer(starts_with("topic"), names_to = "topic", values_to = "value") |>
ggplot(aes(x = author, y = value, fill = topic)) +
geom_col(position = "fill", color = "black") +
coord_flip() +
scale_fill_viridis_d() +
labs(
x = "Topics",
y = "%",
fill = "Authors",
caption = "Source: economania.hu"
) +
theme(
legend.position = "bottom"
)