Readings and class materials for Tuesday, September 26, 2023
Motivation
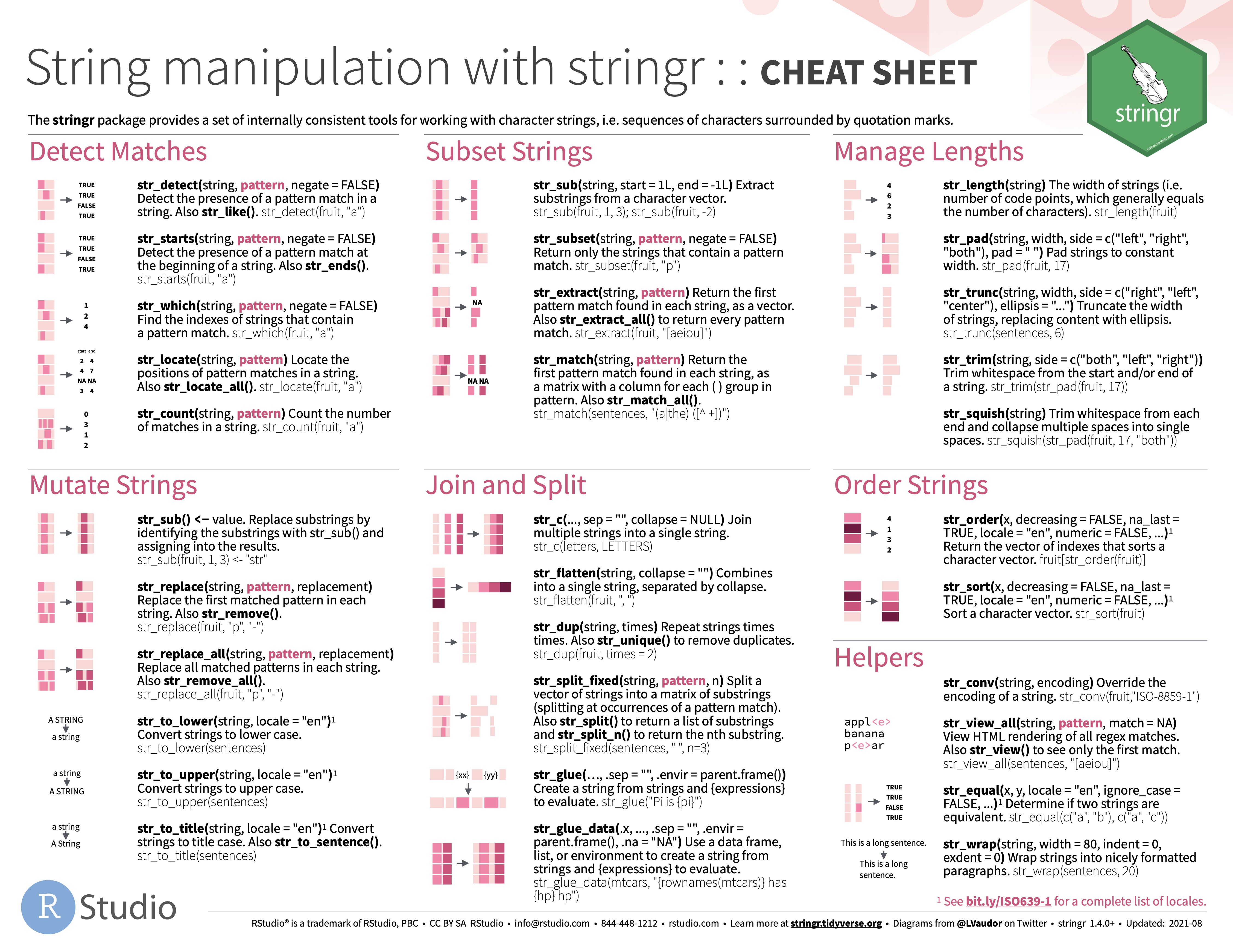
“Strings are not glamorous, high-profile components of R, but they do play a big role in many data cleaning and preparation tasks. The stringr package provides a cohesive set of functions designed to make working with strings as easy as possible.”
All functions within stringr are prefixed with str_ and require a vector of strings as the primary argument. This design choice facilitates the effortless identification of the desired string manipulation function (just type “str_” and use the TAB to browse).
# A tibble: 5 × 2
courses contain_letter
<chr> <lgl>
1 Big data TRUE
2 Behavioral economics TRUE
3 Dynamic macroeconomics 2 TRUE
4 Communication TRUE
5 Economic instituions TRUE
Tip
Each of the regex expressions presented previously has an opposite. The same code in upper case. For instance, \\W is for non-letter characters (numbers or white-spaces)
str_extract(x, "[\\d/-]{3,}")%>%# digit, / or - and more than 3str_remove("[/-]$")%>%# if it is at the endstr_remove("^[/-]")# if it is at the beginning
[1] "2022/09/14"
Caution
Those who want to work with webscraping and/or text analysis tools will really need to learn how to use the {stringr} functions!
Here the . refers to anything, and * denotes any repetition. Thus .* before the pattern means anything before the pattern, and .* after the pattern means anything after the pattern.