In the context of linear regression, we have examined a case where we have a clear understanding of how the value of the output variable follows from the explanatory variables: as a linear combination with some noise.
On the contrary, another approach in a different culture does not aim to describe the “data generating process” that relates x to y, but rather aims to create an algorithm that accurately estimates the target variable. This approach includes neural networks and tree-based models, which were considered innovative in the 1980s. These tools have advanced to a level by the early 21st century where they are capable of tasks such as speech recognition, image recognition, and predicting nonlinear time series. The key is to focus on giving “good predictions”.
Okay… How do we define “good predictions”?
Overfitting
We can demonstrate overfitting, which refers to the use of a overly fitted model, by using a simple example where we fit a model using Ordinary Least Squares (OLS) method. Overfitting occurs when the model overly adapts to the training data and is unable to generalize well to new, unseen data.
In the following steps, I will demonstrate how to create an overfitted model:
set.seed(123)x<-runif(100, 0, 10)y<-2*x+rnorm(100, mean =0, sd =3)# linear dependency with noisetrain_indices<-sample(1:100, 70)train_df<-tibble(x, y)%>%slice(train_indices)test_df<-tibble(x, y)%>%slice(-train_indices)models<-map(1:20, ~lm(y~poly(x, degree =.x), data =train_df))map_dfr(models, broom::glance)
test_r2<-map_dbl(models, ~{augmented<-broom::augment(.x, newdata =test_df)cor(x =augmented$y, y =augmented$.fitted)})fitted_values<-map_dfr(models, ~{broom::augment(.x, newdata =tibble( x =seq(from =0, to =10, length.out =100)))}, .id ="p")%>%mutate( p =factor(p, levels =as.character(1:100)))bind_rows(train_df%>%mutate(type ="training"), test_df%>%mutate(type ="testing"))%>%mutate( type =factor(type, levels =c("training", "testing")))%>%ggplot(aes(x =x, y =y))+geom_point()+geom_line(data =fitted_values, aes(x =x, y =.fitted, color =p), show.legend =FALSE)+facet_wrap(~type)+custom_theme+theme( panel.border =element_rect(color ="black", fill =NA),)
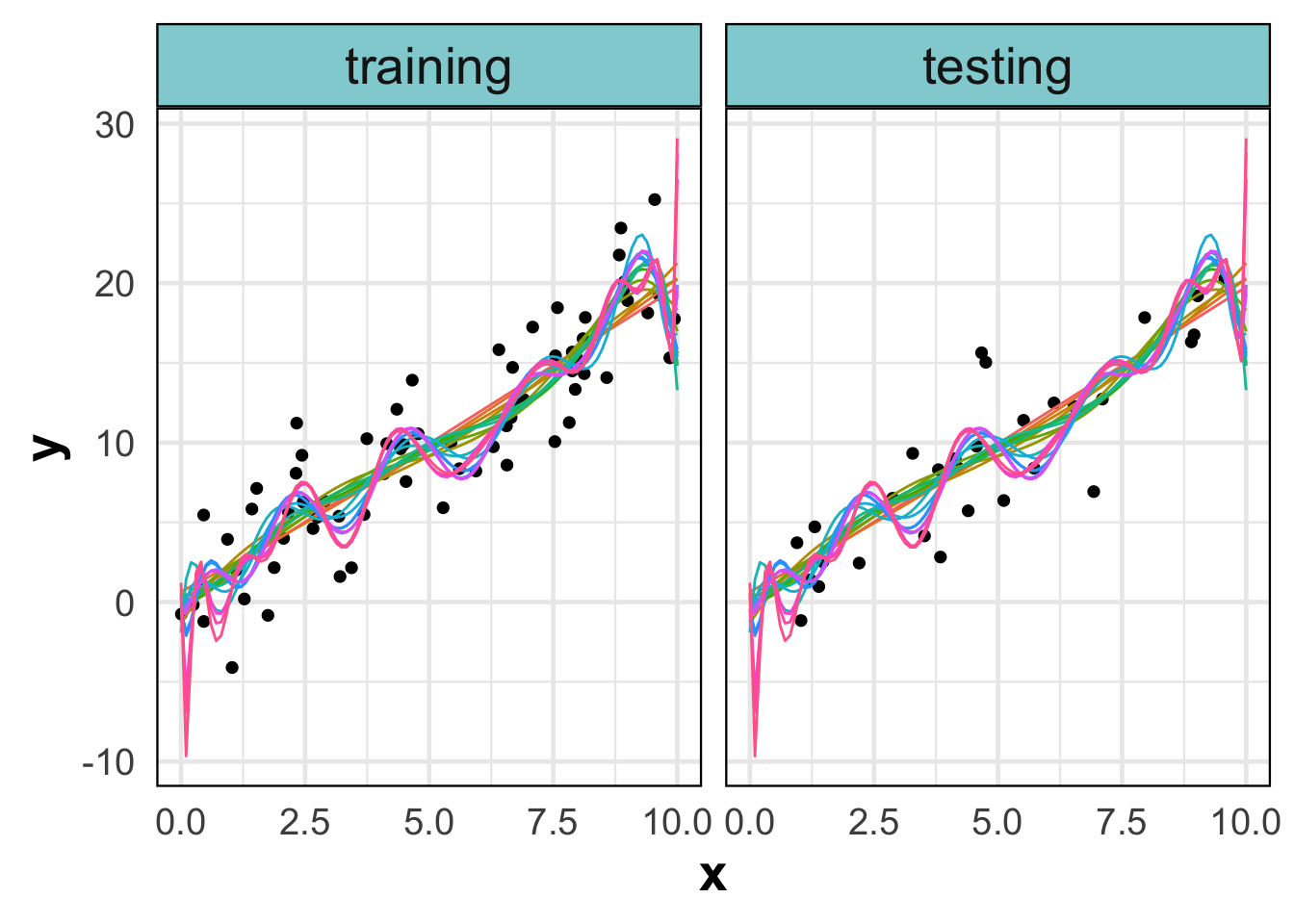
As the degree of the polynomial increases, the model becomes more complex and the training error decreases. However, the test error increases as the model becomes more complex. This is because the model is overfitted to the training data and does not generalize well to new data. The figure above shows how the model fits the training data and the test data. As the model becomes more complex, it captures the noise in the training data and does not generalize well to the test data.
Therefore, when evaluating the goodness of a model, if generalizability is the objective, we never assess the fit on the points on which it was built, but rather separate a portion of the observed data and train the model on one part while evaluating it on the other. This is called cross-validation.
Decision Tree🌲
Decision trees are a type of supervised learning algorithm that can be used for both regression and classification tasks. Their goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. Decision trees are easy to interpret and visualize, and they can easily capture nonlinear relationships. However, they are prone to overfitting.
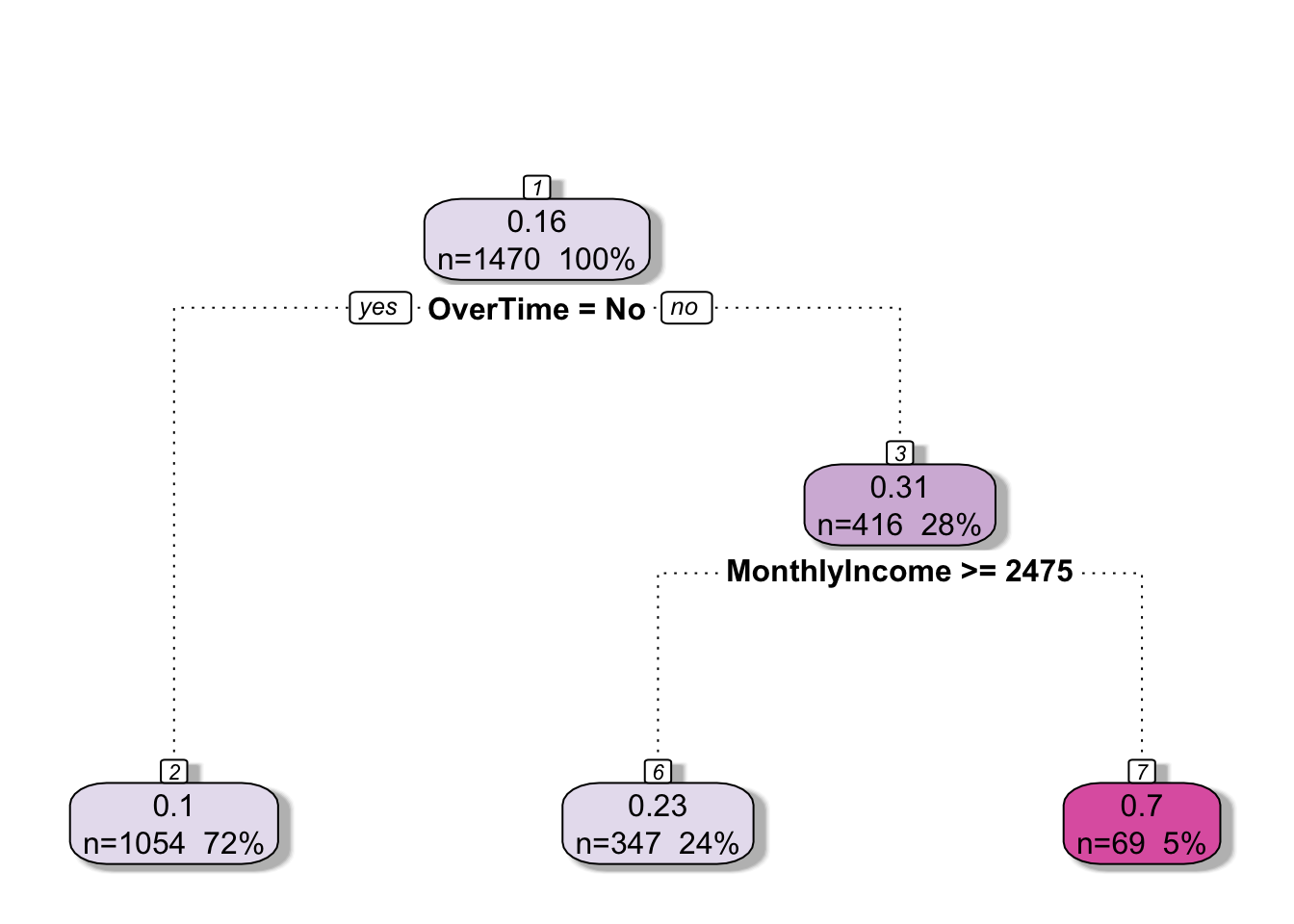
rattle::fancyRpartPlot(attrition_tree, palettes ='PuRd', sub =NULL)
CART
The aim is to minimize the average heterogeneity of the tree’s leaves, weighted by numbers. If the task is classification, then the heterogeneity of a leaf is measured by the Gini index, which is the probability that two randomly selected elements from the leaf are of different classes. The Gini index is defined as follows:
\[
G = 1 - \sum_{i=1}^{k} f_i^2
\] If the task is regression, then the heterogeneity of a leaf is measured by the Sum of Squared Error of the target variable. The variance is defined as follows:
\[
SSE = \sum_{i=1}^{n} (y_i - \bar{y})^2
\]
If a predictor is categorical, then the tree will split the data into subsets based on the categories of the predictor. If a predictor is continuous, then the tree will split the data into subsets based on a deciles of the predictor.
The tree will continue to split the data until the stopping criteria is met. The stopping criteria can be defined by the minimum number of observations in a leaf node, the maximum depth of the tree, or the minimum improvement in the Gini index or Sum of Squared Error (complexity parameter, cp).
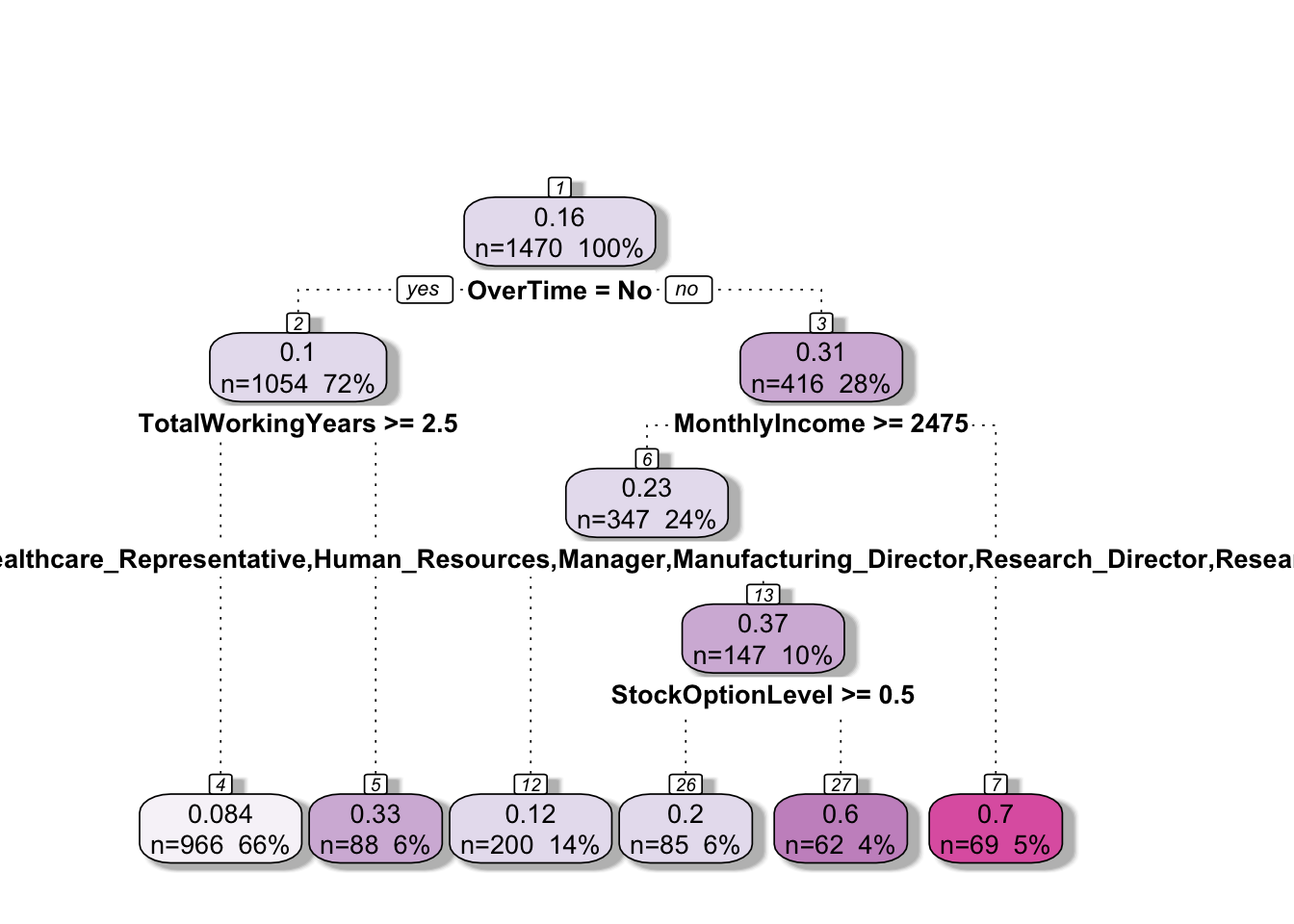
Let’s decrease the complexity parameter to see how the tree changes.
attrition%>%mutate(Attrition =Attrition=="Yes")%>%rpart(formula =Attrition~., cp =.021)%>%rattle::fancyRpartPlot(palettes ='PuRd', sub =NULL)
How should we determine the complexity parameter? We can use cross-validation to determine the optimal complexity parameter for best predictions on a test set or if visualising the tree is the goal, we can try different values to draw a tree that highlights the splits that we find to be important, but the reader can still understand the tree.
Advantages of Decision Trees
Intuitive Understanding: Decision trees provide a clear and easy-to-understand model structure, which makes them particularly useful for interpretability. They mimic human decision-making processes, making their logic transparent. I personally recommend their use for descriptive statistics. They possess a highly intuitive and articulate approach to describe the data (example).
No Need for Feature Scaling: These models don’t require feature normalization or standardization. They can handle varied scales of data effectively.
Handle Both Types of Data: Capable of handling both numerical and categorical variables.
Non-Parametric Method: As a non-parametric method, decision trees make no assumptions about the underlying distributions of the data, which is beneficial for analysis with less data preprocessing.
Capability of Feature Selection: They inherently perform feature selection by prioritizing the most informative features at the top splits.
Easy to Visualize: Their tree-like structure allows for easy visualization, aiding in understanding the decision-making process.
Can Model Non-Linear Relationships: Capable of capturing non-linear relationships between features and labels.
Disadvantages of Decision Trees
Overfitting: Decision trees are prone to overfitting, especially with complex trees. They can become too tailored to the training data and fail to generalize well.
Instability: Small variations in the data can result in a completely different tree structure. This lack of robustness can be a significant issue.
Not Suitable for Extrapolation: Decision trees cannot extrapolate or make predictions outside the range of the training data.
Poor Performance with Unbalanced Data: They can create biased trees if some classes dominate the dataset, leading to skewed decisions.
Difficulty with Large Number of Classes: The performance and computation time can degrade with a large number of target classes.
Random Forest 🌲🌴🌳
Random forest is an ensemble learning method that combines multiple decision trees to create a “forest” that can make more accurate predictions than a single decision tree. It can be used for both regression and classification tasks. Random forest is a bagging technique and uses bootstrap sampling to create multiple decision trees. It also uses random feature selection to create each decision tree. The final prediction is the average prediction of all the decision trees.
Multivariate adaptive regression splines (MARS) is a non-parametric regression method that can be used for both regression and classification tasks. It is a type of regression that uses piecewise linear basis functions to model the data. It is similar to decision trees, but it uses linear combinations of basis functions instead of a tree structure. It is also similar to polynomial regression, but it uses piecewise linear functions instead of polynomials. MARS is a type of additive model, which means that it is a linear combination of basis functions. The basis functions are defined as follows:
\[
h(x) = \beta_0 + \sum_{j=1}^{k} \beta_j B_j(x)
\] where \(B_j(x)\) is a basis function. The basis functions are defined as follows:
\[
B_j(x) = \max(0, x - c_j)_+^p
\] where \(c_j\) is a knot and \(p\) is the degree of the basis function. The basis functions are piecewise linear functions with a knot at \(c_j\). The basis functions are also known as hinge functions. The basis functions are added to the model one at a time. The first basis function is a constant function. The second basis function is a constant function plus a hinge function. The third basis function is a constant function plus two hinge functions. The fourth basis function is a constant function plus three hinge functions. The process continues until the model reaches the maximum number of basis functions or the maximum number of basis functions that can be added without increasing the error. The model is then pruned to remove basis functions that do not improve the error.
The model starts from a null model.
In each step, it adds the new hinge function pair that minimizes \(R^2\) the most, where a hinge function is a variable pair \(max(x - c, 0)\) and \(max(c - x, 0)\), with \(x\) being the original variable and \(c\) being a threshold value.
This creates an overfitted model, so it eliminates the variables that prove to be redundant using Cross-validation method.
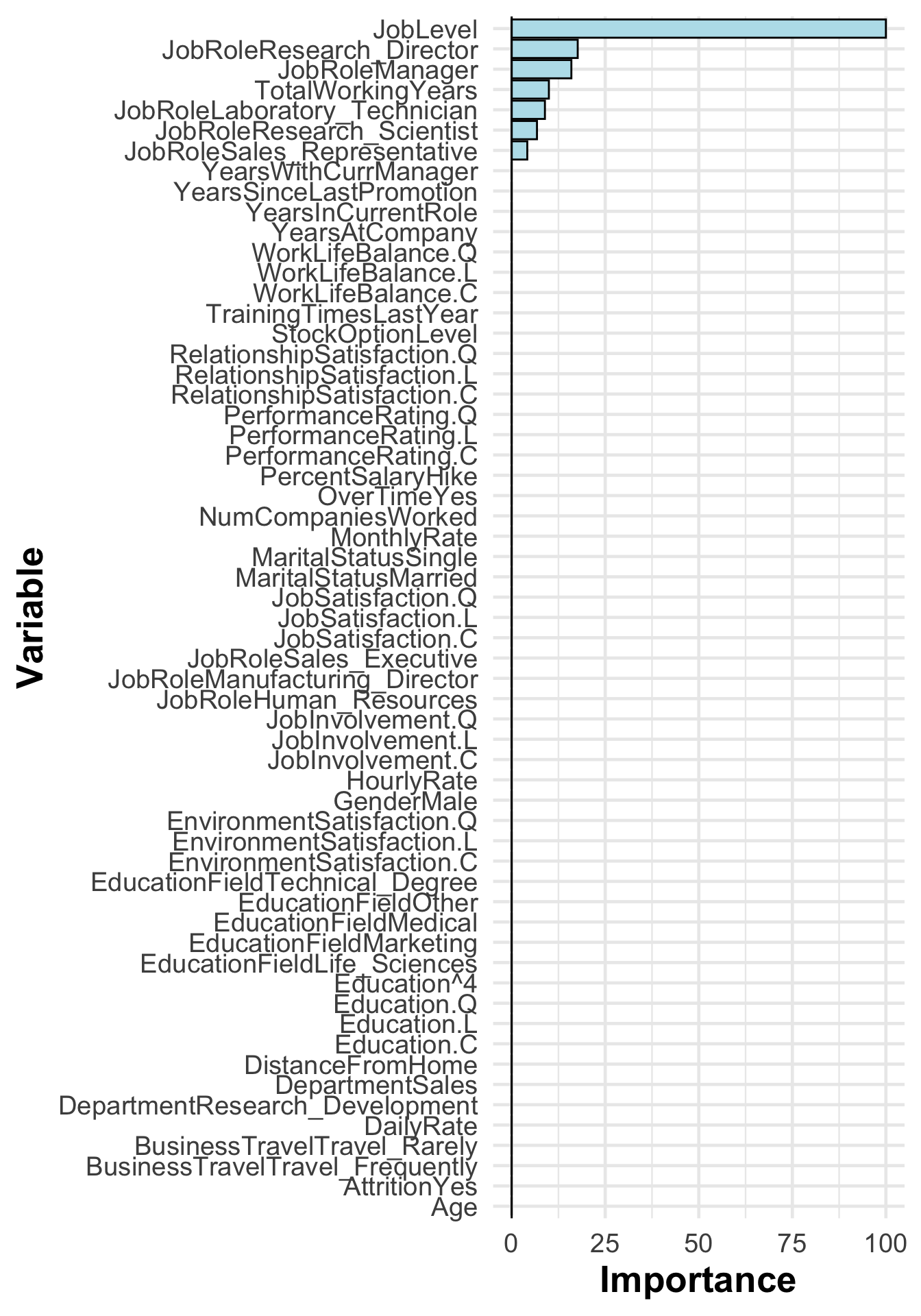
fit<-earth::earth(formula =MonthlyIncome~., data =attrition, degree =2)
fit
Selected 14 of 14 terms, and 7 of 59 predictors
Termination condition: RSq changed by less than 0.001 at 14 terms
Importance: JobLevel, JobRoleResearch_Director, JobRoleManager, ...
Number of terms at each degree of interaction: 1 6 7
GCV 1067435 RSS 1498425944 GRSq 0.9518739 RSq 0.9539798
Call: earth(formula=MonthlyIncome~., data=attrition, degree=2)
coefficients
(Intercept) 5638.0557
JobRoleManager 3295.9923
JobRoleResearch_Director 3351.7660
h(2-JobLevel) -2765.9146
h(JobLevel-2) 3496.8878
h(6-TotalWorkingYears) -607.0069
h(TotalWorkingYears-6) 51.2191
JobRoleLaboratory_Technician * h(TotalWorkingYears-6) -199.8807
JobRoleResearch_Scientist * h(TotalWorkingYears-6) -141.6059
JobRoleSales_Representative * h(TotalWorkingYears-6) -201.7847
h(2-JobLevel) * h(TotalWorkingYears-7) 152.9745
h(2-JobLevel) * h(7-TotalWorkingYears) 397.6352
h(JobLevel-2) * h(TotalWorkingYears-15) -28.8981
h(JobLevel-2) * h(15-TotalWorkingYears) -121.2103
Selected 14 of 14 terms, and 7 of 59 predictors
Termination condition: RSq changed by less than 0.001 at 14 terms
Importance: JobLevel, JobRoleResearch_Director, JobRoleManager, ...
Number of terms at each degree of interaction: 1 6 7
GCV 1067435 RSS 1498425944 GRSq 0.9518739 RSq 0.9539798
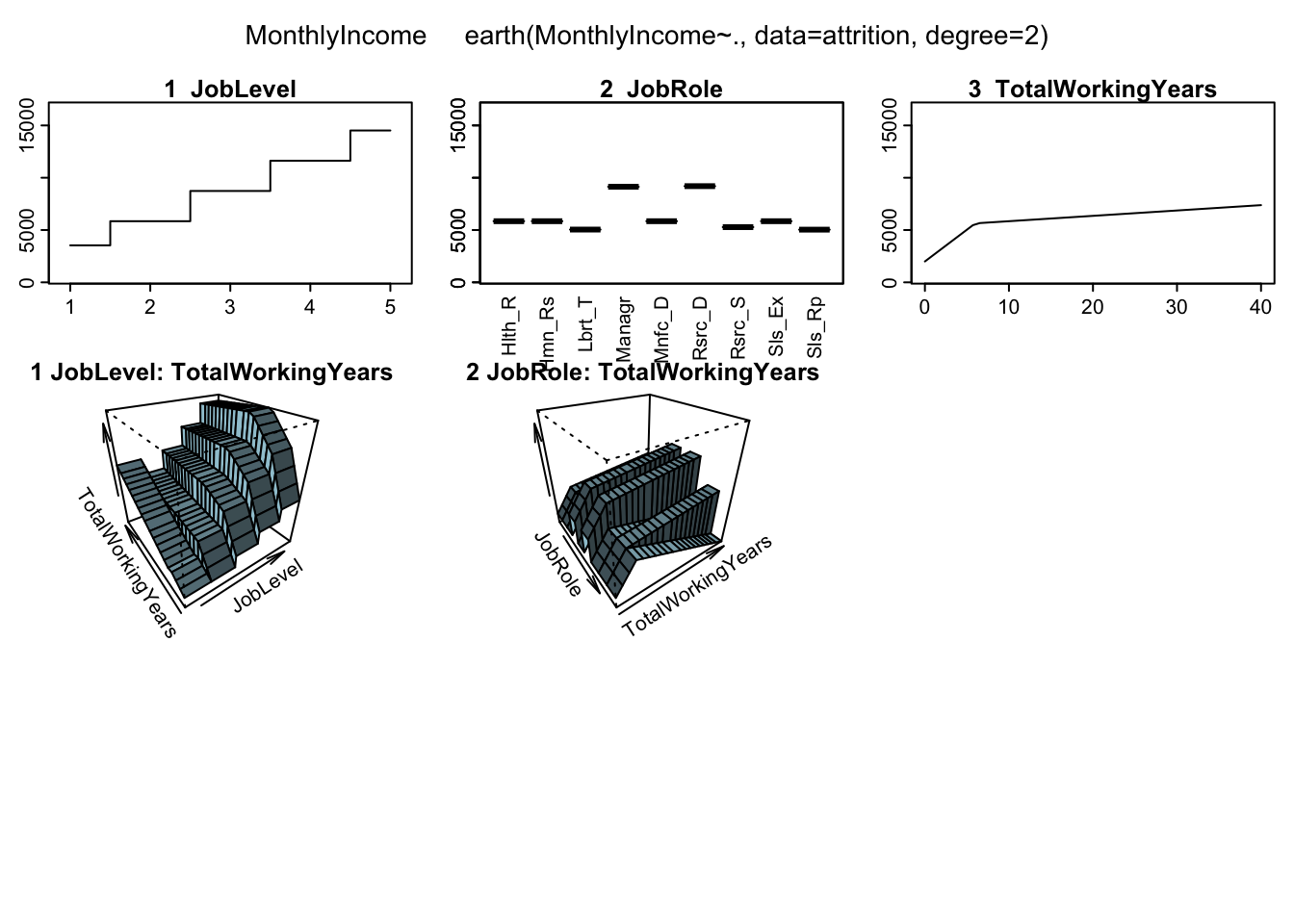
It can be quite challenging to navigate through the meaning of these coefficients… Let’s visualise the response over a range of predictor values. A solution can be found in the plotmo package. It keeps the value of every predictor at a constant (median or mode) and varies the value of the predictor of interest. The plot shows the predicted response as a function of the predictor of interest, with the other predictors held constant. It can also be used to visualize the relationship between the response and a pair of predictors.
plotmo::plotmo(fit)
plotmo grid: Age Attrition BusinessTravel DailyRate Department
36 No Travel_Rarely 802 Research_Development
DistanceFromHome Education EducationField EnvironmentSatisfaction Gender
7 Bachelor Life_Sciences High Male
HourlyRate JobInvolvement JobLevel JobRole JobSatisfaction
66 High 2 Sales_Executive Very_High
MaritalStatus MonthlyRate NumCompaniesWorked OverTime PercentSalaryHike
Married 14236 2 No 14
PerformanceRating RelationshipSatisfaction StockOptionLevel TotalWorkingYears
Excellent High 1 10
TrainingTimesLastYear WorkLifeBalance YearsAtCompany YearsInCurrentRole
3 Better 5 3
YearsSinceLastPromotion YearsWithCurrManager
1 3
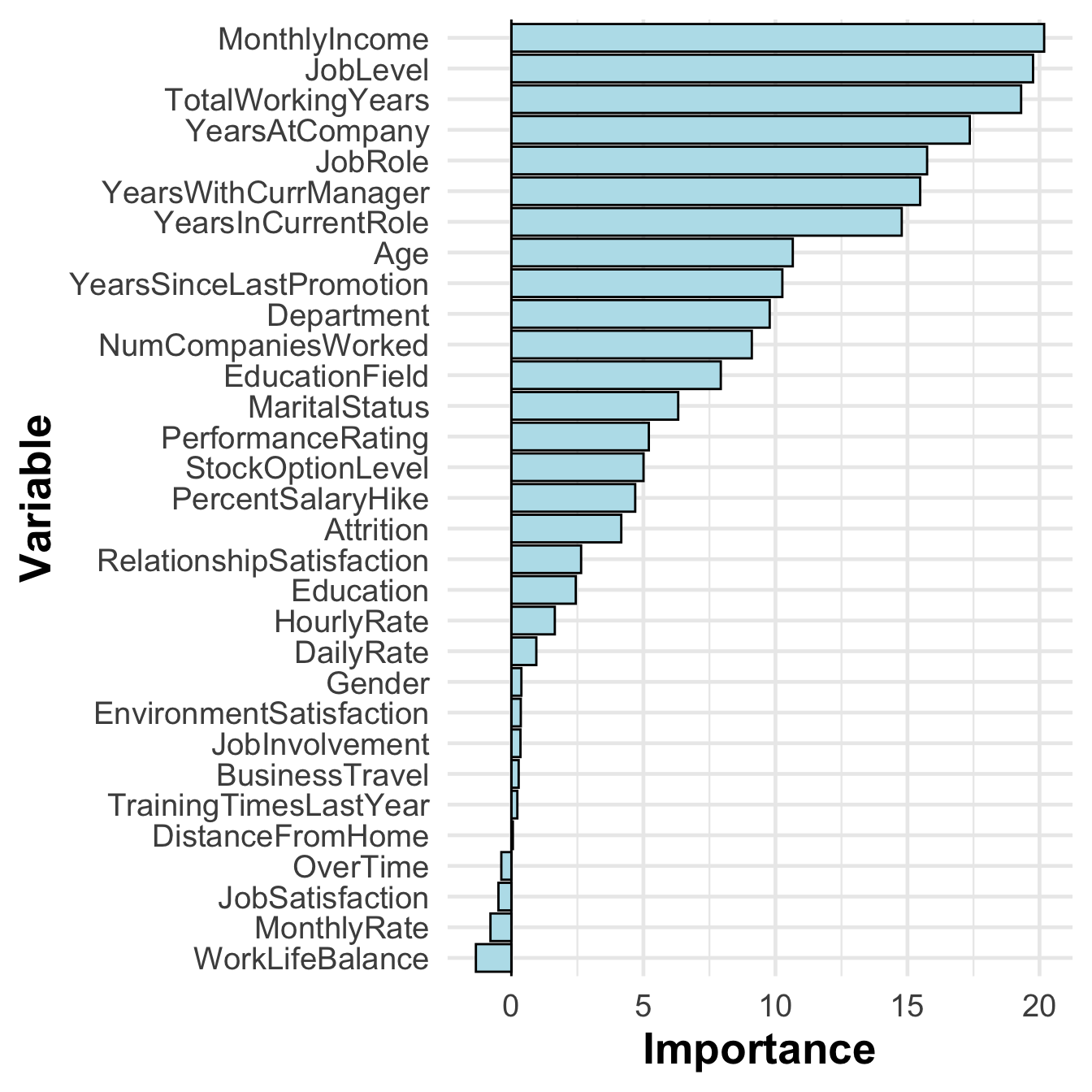
Additionally, calculating the importance of variables can aid in the interpretation of the model. This can be easily done using the vip package. However, in the case of the MARS model, the Variable Importance (VI) is calculated differently. By applying our advanced documentation reading skills, we can find the following:
The earth package uses three criteria for estimating the variable importance in a MARS model (see evimp for details):
The nsubsets criterion (type = “nsubsets”) counts the number of model subsets that include each feature. Variables that are included in more subsets are considered more important. This is the criterion used by summary.earth to print variable importance. By “subsets” we mean the subsets of terms generated by earth()’s backward pass. There is one subset for each model size (from one to the size of the selected model) and the subset is the best set of terms for that model size. (These subsets are specified in the $prune.terms component of earth()’s return value.) Only subsets that are smaller than or equal in size to the final model are used for estimating variable importance. This is the default method used by vip.
The rss criterion (type = “rss”) first calculates the decrease in the RSS for each subset relative to the previous subset during earth()’s backward pass. (For multiple response models, RSS’s are calculated over all responses.) Then for each variable it sums these decreases over all subsets that include the variable. Finally, for ease of interpretation the summed decreases are scaled so the largest summed decrease is 100. Variables which cause larger net decreases in the RSS are considered more important.
The gcv criterion (type = “gcv”) is similar to the rss approach, but uses the GCV statistic instead of the RSS. Note that adding a variable can sometimes increase the GCV. (Adding the variable has a deleterious effect on the model, as measured in terms of its estimated predictive power on unseen data.) If that happens often enough, the variable can have a negative total importance, and thus appear less important than unused variables.
vip::vi(fit, type ="gcv")%>%mutate(Variable =fct_reorder(Variable, Importance))%>%ggplot()+geom_col(aes(Importance, Variable))+geom_vline(xintercept =0)
Variable importance for MARS
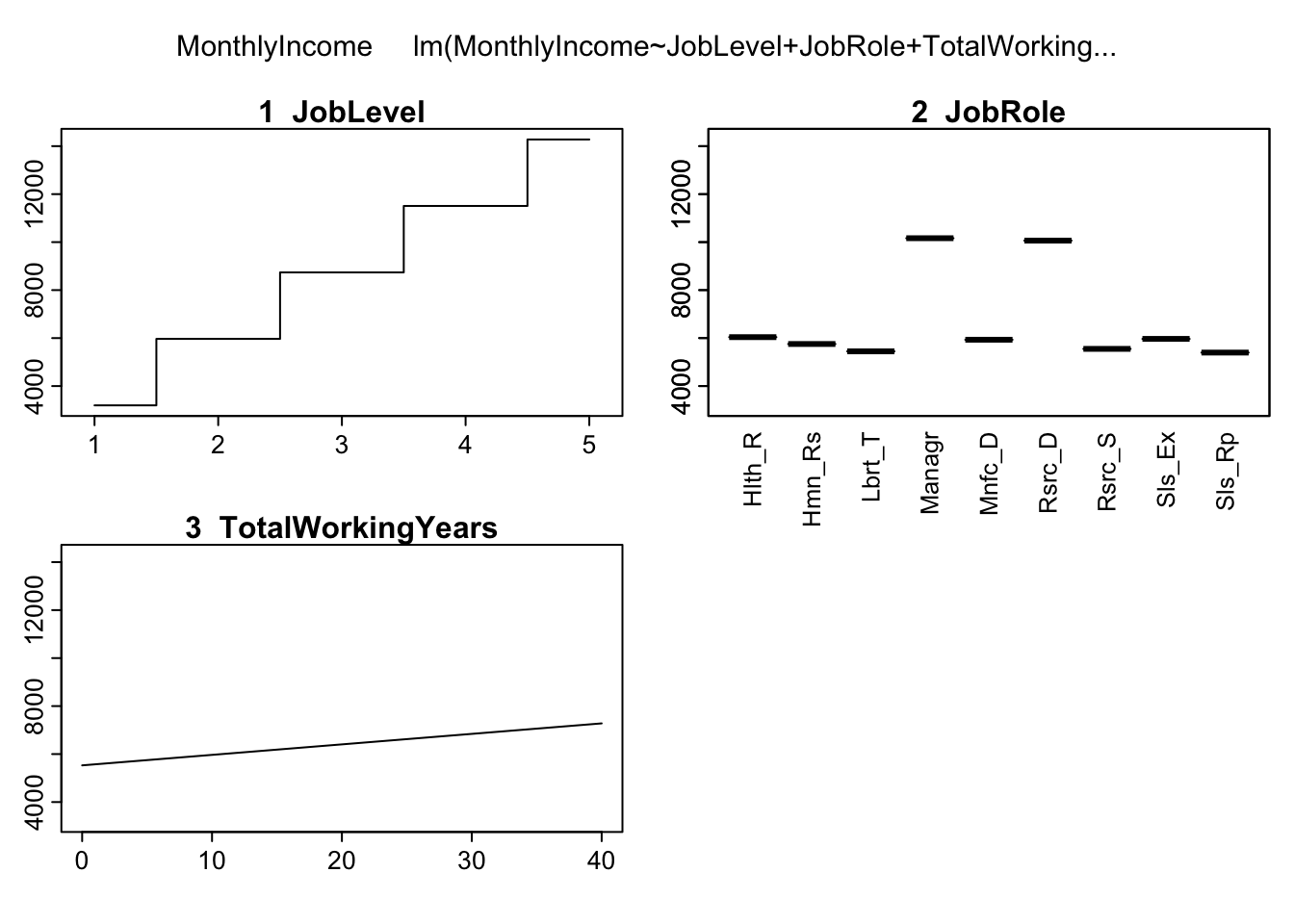
We might see that the monthly income increases with the increasing the working years, but the relationship is not linear. The slope decreases after 6 years. This function can also be used for simple OLS models if it becomes complex (or you can develop a similar solution to any other model)
lm(formula =MonthlyIncome~JobLevel+JobRole+TotalWorkingYears, data =attrition)%>%plotmo::plotmo()
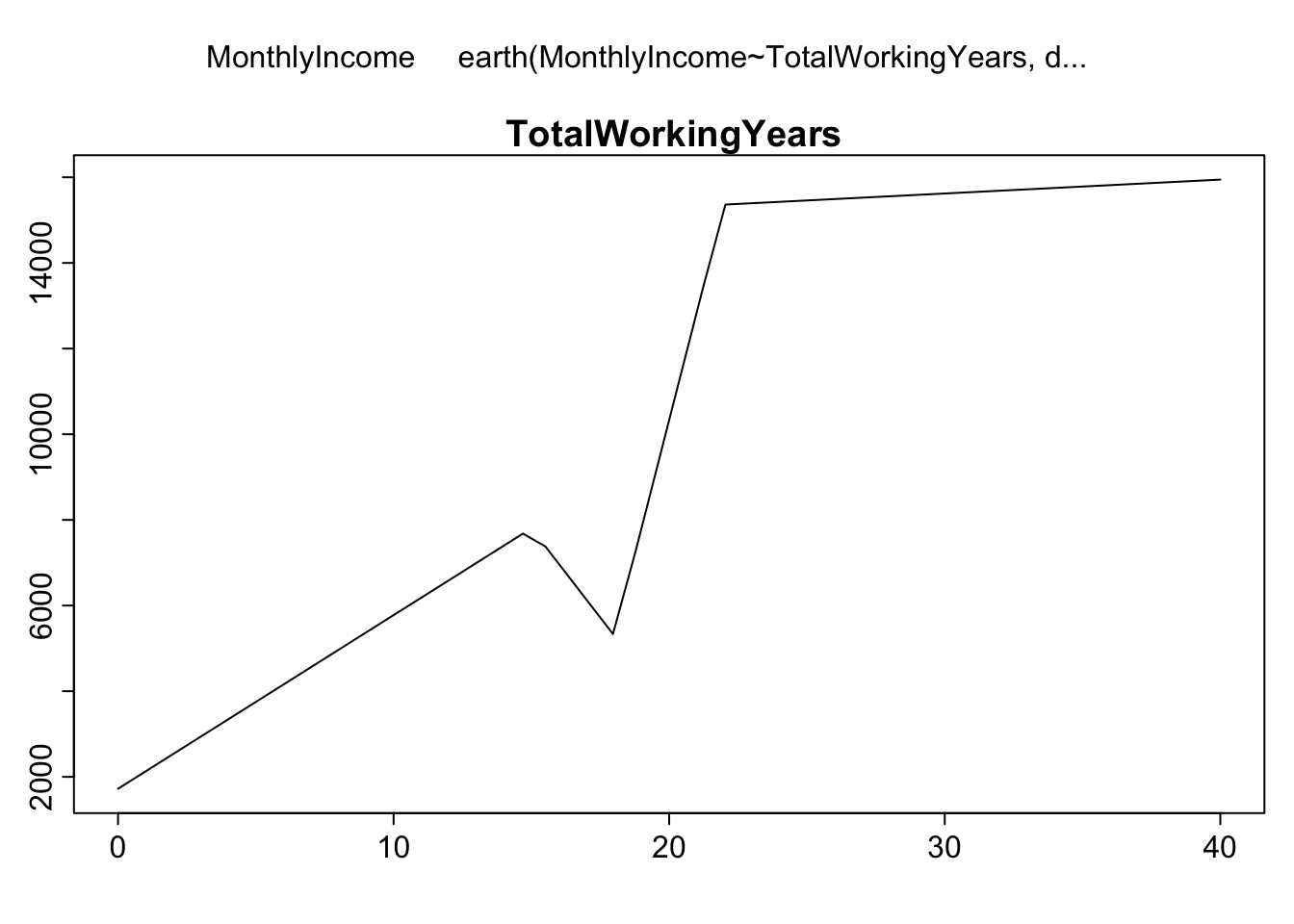
fit<-earth::earth(formula =MonthlyIncome~TotalWorkingYears, data =attrition, degree =2)summary(fit)
Call: earth(formula=MonthlyIncome~TotalWorkingYears, data=attrition, degree=2)
coefficients
(Intercept) 7804.0544
h(15-TotalWorkingYears) -405.4382
h(TotalWorkingYears-15) -834.0226
h(TotalWorkingYears-18) 3348.9434
h(TotalWorkingYears-22) -2482.4637
Selected 5 of 6 terms, and 1 of 1 predictors
Termination condition: RSq changed by less than 0.001 at 6 terms
Importance: TotalWorkingYears
Number of terms at each degree of interaction: 1 4 (additive model)
GCV 7487091 RSS 10841924236 GRSq 0.6624387 RSq 0.6670189
plotmo::plotmo(fit)
It is worth noting here that the implemented algorithm always represents the hinge function as max(x-c, 0) or max(c-x, 0), and only displays the x-c or c-x part for the coefficients. Therefore, it follows that the value of the hinge function denoted as h(15-TotalWorkingYears) decreases as work experience increases. Hence, the corresponding negative coefficient implies that the expected salary decreases as work experience increases and is below 15 years.